Nearly four years after this was written, there is still no satisfying solution to providence tracking in a data science workflow. The few solutions that do exist tend to be too opinionated to catch on.
I've gotten a lot of mileage out of hacking some provenance tracking into a plain-old-Makefile workflow, but it's hard to balance human-readable makefiles and the amount of hackery it takes.
I would love to know what you think about Domino Data Lab's solution. I feel pretty strongly about provenance tracking, especially being able to go: artifact <-> experiment <-> code / data <-> environment, and our solution implements those linkages.
It looks like the right approach for building a platform from scratch, the problem is that I am working with an existing in-house platform. Makefiles are so un-opinionated that they fit in quite nicely, all I really want is a more modern Make.
I've tried a few other techniques, but there is something that is really hard to beat about the plain Makefile. Eventually, it can become unwieldy, but for small-medium projects, it's a life saver. Combine that with git, and you've got a pretty robust system. The only real downside is that when you have very large initial inputs, it isn't practical to store those in the same repository.
That is my goto combinations for bioinformatics workflows that don't need to run on a cluster. (A Makefile variant of mine is my go-to for clusters). I've experimented with Docker workflows, which while in theory are nice, you'll always require some sort of organizing script to document the analysis. (Docker is still nice for capturing program versioning/configuration though!)
I usually work with data on an internal cloud anyway, so instead of storing data on my local disk I just keep text files that contain the URI of the cloud resource. I treat the cloud resources as immutable once created so that the "pointer" file's modified time is consistent with the modified time of the data on the cloud.
I really like their approach, but their template is too opinionated towards python + makefiles. At my company we use mixes of R, python and Scala, together with airflow. We have been toying with our own templates, and should release them eventually
Yes, I actually only use Python for notebooks, so I mostly ignore the Python specific parts. I think their data/ directory structure (along with keeping it out of the repo) is a sane approach though.
(I don't actually use their template, I just use the directory layout as guidance)
Yeah I tend to be pretty meticulous about this too, but it takes a large amount of effort and there's no incentive for most people to do it unfortunately.
I've been writing Makefiles too, but I don't feel like I can explain with a straight face to others that they should do it too...
I will also throw in my (biased, as I work on the project) suggestion to take a look at Pachyderm (http://pachyderm.io/). It is open source, language agnostic, and distributed. Plus it automatically tracks the provenance of all of your data pipelines, regardless of language or parallelism over your data.
Basically you set up data pipelines, where the input/output of each stage is versioned (like "git for data"). That way you have versioned sets of your data (e.g., training data), but you also can know things like exactly what model was used to produce which result, what data was used to train that particular model, what transformations occurred on that training set, etc.
Things like Airflow and Luigi are, no doubt, useful for data pipelining and some workflows (depending on what language you are working with). However, by combining pipelining and data versioning in a unified way, Pachyderm naturally lets you handle provenance of complicated pipelines, have exact reproducibility, and even do interesting things like incremental processing.
You should also check out Pachyderm, github.com/pachyderm/pachyderm. Pachyderm builds provenance tracking directly into your data so every results has provenance through every bit of data and code that was used to create it.
SciLuigi adds a simple level of audit logging to Luigi [1] (See the AuditTrailHelpers mixin in https://github.com/pharmbio/sciluigi/blob/master/sciluigi/au... for details), together with an API that makes it much easier to work do changes to the workflow dependency graph, when you're in development/exploratory phase.
Personally moved to improve on the ideas in SciLuigi, but replacing Luigi with Go's concurrency primitives, in SciPipe [2].
In SciPipe, an accompanying ".audit.json" file, containing the full history of commands and parameters used to create every single output file of the workflow (even intermediate ones), to help keep track of how each file was produced.
Among lightweight solutions, the popular ones these days seem to be NextFlow [3], Snakemake [4], BPipe [5] and others. You'd really have to check out the "awesome pipelines" [6] list, to get any kind of overview.
When more infrastructure setup is feasible, I think PachyDerm [7] (mentioned elsewhere in the thread) looks really powerful with its "Git for data" approach. Something I'd wish to use as an overarching solution within which to run my SciPipe workflows.
Philips CDE tool [1] looks like such a beautiful thing!
> "Prepend any set of Linux commands with the "cde" binary, and CDE will run them and automatically package up all files (e.g., executables, libraries, plug-ins, config/data files) accessed during execution."
Then, put this in a Docker if you want, but so awesome not be required to do that!
I think more orthogonality is needed, and less fluff and accidental complexity in all its forms, including "buzzword" tech stacks.
Lately I have been looking into data science workflows and tools. One of the most promising ones I have seen is https://pachyderm.io
Data is stored and versioned on a custom docker-like filesystem. Processes are defined by yaml and run based on incoming new data to the filesystem. The processes can be versioned with the data and results, written into the fs are also versioned. It seems like a very good approach to many of the difficulties.
I'm not affiliated with them, but vcs helped my programming so much that I am looking for the best applications of versioning to data management.
Edit: this is mainly concerned with the center box, analysis and records. For provenance you get a consistent snapshot of the incoming data, but that data is fixed. For my work consistency and repeatability is more important than accuracy with respect to an external source.
> As an extreme example, my former officemate Cristian Cadar used to archive his experiments by removing the hard drive from his computer after submitting an important paper to ensure that he can re-insert the hard drive months later and reproduce his original results.
Perhaps it would be an idea to use a virtual machine such as VirtualBox instead?
I have recently started to think about designing a good workflow for this kind of thing, based on tools like Docker, Nix, Camlistore, etc. The following questions will need to be addressed:
1. Setting up the requisite environment inside a container. Making all "hidden state" explicit -- by specifying the state of every object in the dependency tree (including specifying things like the seed for a random number generator, or a particular noise source).
2. Should the experimentation/improvements happen inside the container, or should it happen on a desktop, with a snapshot of the project (when committed) generating a container version? One could update a Docker image depending on git tags, with project diffs corresponding to container layers.
- It would be great if one could use a script to specify the "state" in a project to be able to move it into a container, at any point in the process.
3. Could one store the output files using some form of content-addressable-memory, so that each output file remembers the "context" in which it was generated?
Full Disclosure, I am the Chief Data Scientist of Domino Data Lab (https://www.dominodatalab.com), a company that builds tools for collaboration/scaling of data science a quantitative research teams. I spoke about our view on data provenance at UseR! 2016 and if you're curious you can watch the video here https://blog.dominodatalab.com/providing-digital-provenance-.... The rest of this comment is not about reproducibility and provenance however, it's mostly about collaboration.
I really like this write-up. It's really quite prescient for a blog post from 2013! There have been amazing advances in the tooling for individual data scientists. RStudio, Jupyter, and Zeppelin notebooks have provided a really fluid REPL for data science. This has really compressed the workflows he discusses, and provides feedback and direction to data scientists much more quickly than the program oriented process. It’s interesting to note how an unexpected direction (notebooks) can impact praxis.
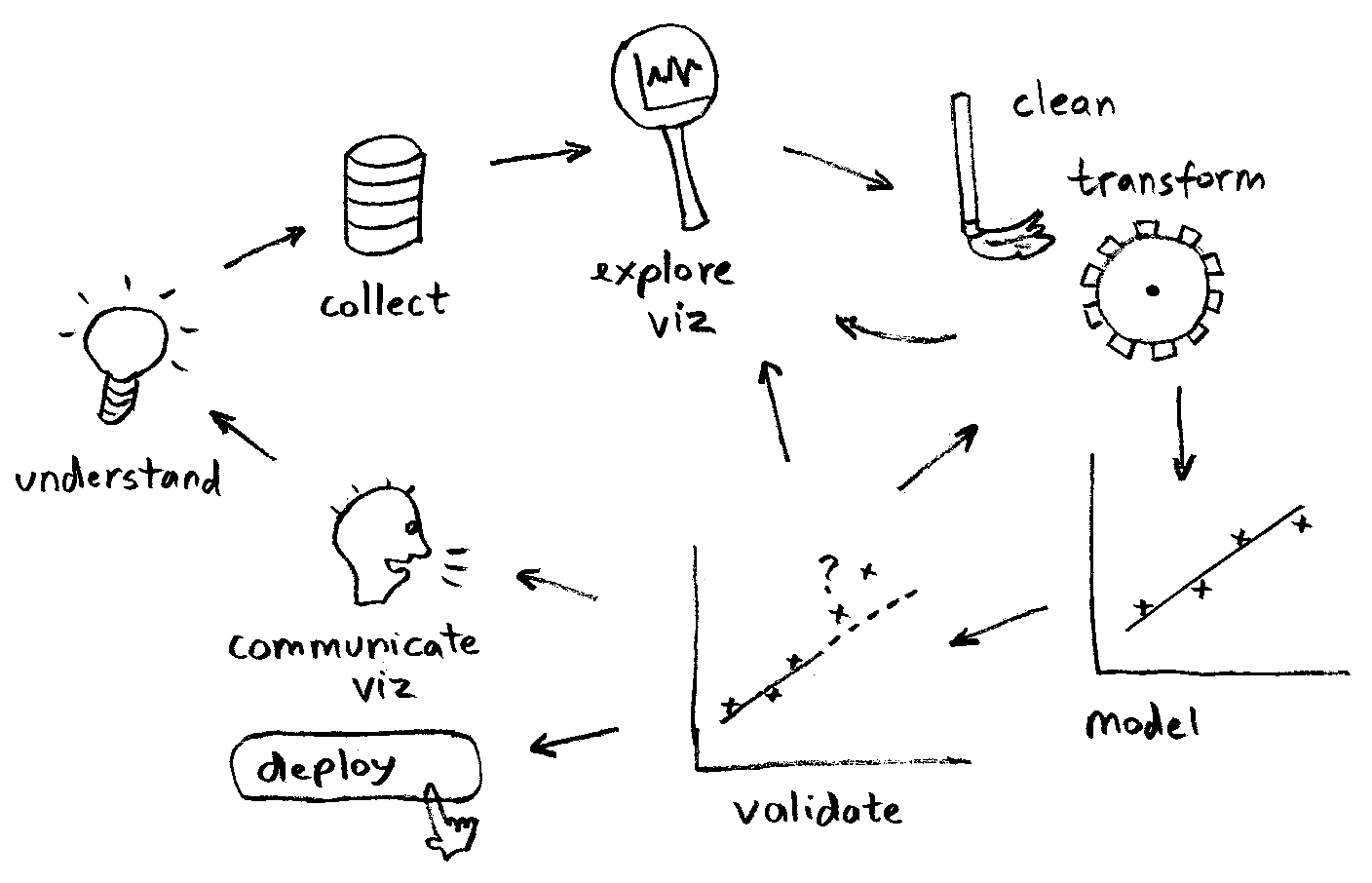
I refer to these two visualizations of the data science process often. The first is by Szilard Pafka, and it details the workflow he has experienced by having models in production for well over a decade at this point. It’s available here:
What I really like about this is that it really shows the centrality of model validation. From model validation, you can often find yourself having to go back to exploration, cleaning/transformation, etc. Guo’s diagram calls this preparation, which only has an out-arrow. Preparation is not something that is one-and-done, you return to it often in the DS lifecycle.
I also really like this particular visualization, it’s from UC Berkley and it’s the “understanding science” model of the scientific process.
Much like Guo’s or Szilard’s diagram, the centrality of testing/validation/analysis is telling. The nature of collaboration is more explicit in this model. In the post, Guo states:
Lastly, data scientists often collaborate with colleagues by sending them partial results to receive feedback and fresh ideas. A variety of logistical and communication challenges arise in collaborations centered on code and data sharing." I think this is particularly insightful. The challenges of scaling a data science team are different often than those of scaling a software team (for example), and I think he foresaw that before a lot of folks did.
I agree with this, but with two additional points. Often colleagues are from very different disciplines. Business stakeholders or subject matter experts that don’t understand the analysis, but they understand some feature/outcome with depth. In the Berkeley understanding science diagram, I really like that it’s explicitly called out as “community analysis and feedback.” I think that’s an important distinction that it’s not just other data scientists that provide feedback, the artifacts of the DS process have to be accessible to a wide assortment of backgrounds and skills.
It’s also interesting that from community analysis and feedback you can find yourself in any of the stages, exploration/discovery, testing, and benefits and outcomes. This is why organizations find themselves challenged to measure the progress of their DS teams, and why forecasting the amount of effort that will be required can be daunting without wide error bars. Data science is unique in that the data can be correct, the pipeline can be reproducible, the model perform perfectly in cross validation, but when it’s put into production it can be completely wrong. Prediction about prediction is hard.
I do like how all of these models, the Szilard model, the Understanding Science model, and Guo’s model share a lot in common. The loopbacks, the different phases, and the centrality of analysis/testing/validation are shared among all of them. My intuition is that getting that part of the process right, in a fluid way that scales beyond one researcher, is often the biggest roadblock to scaling quantitative research.
It also strikes me that a lot of these problems in dissemination have been solved to a large degree in software development. I guess 'writing code everyday' and 'knowing how to architect systems and use software development principles' are getting increasingly less mutually exclusive, which lends itself well to further abstractions.
Distribution is one of the things we deal with most frequently at https://nstack.com. We let data scientists deploy their models into bit-for-bit reproducible modules which run in the cloud and can be composed with various data sources. Because these are semantically versioned and packaged on the server as bit-for-bit reproducible builds, this solves the fact that "one's own operating system and software inevitably get upgraded in some incompatible manner such that the original code no longer runs". Our background was in writing programming languages, so we took a lot of the ideas of type-safety and composition and applied them to this problem.
Actually the most common way we see dissemination solved in enterprises is folks writing back to the warehouse and using Looker / Tableau to visualise, with a workflow like:
Looking forward to jumping into his http://pgbovine.net/cde.html project. We explored a ton of solutions here (including Nix), but ended up settling on btrfs.
>It also strikes me that a lot of these problems in dissemination have been solved to a large degree in software development.
Yeah, this is exactly how we feel too! Git solves this so well for software development which is why Pachyderm (http://pachyderm.io/pfs.html) build a distributed file system with those same principles in mind.
Do a lot of these "data quality" problems go away if you were simply to use a relational DB, and related best practices, like table versioning, PKs, using a last_updated timestamp for each row, etc.?
Shameless plug: looking specifically at the Dissemination Phase part, I can't help but thinking he would love Code Ocean (https://codeocean.com). It addresses each of his points:
- distribute software (execute with a single click)
- reproduce results (published code & data - yours and others' - is archived with its environment)
- collaborate with colleagues (built-in to the system)
(Disclaimer: I work at Code Ocean. We're in beta.)
Agreed. It seems to me that Apache Nifi (for provenance/replay) + jupyter/zepplin/r-studio (for exploring) + airflow (for final workflow) would be a good, open source starting point.
i'm kinda confused what the point of this writeup was? just something to have on your resume? i don't think anybody involved in research let alone data science had anything to gain from it, and it certainly didn't propose any solutions...
{kind=link}
{kind=link}
I've gotten a lot of mileage out of hacking some provenance tracking into a plain-old-Makefile workflow, but it's hard to balance human-readable makefiles and the amount of hackery it takes.