Why are there so many English-first AI models from China? Are they not interested in serving their own population? Or is it that if they publish Chinese-first models it won't get publicity in the West?
CommonCrawl [1] is the biggest and most easily accessible legally acquired crawling dataset around, collecting data since 2008. Pretty much everyone uses this as their base dataset for training foundation LLMs and since it's mostly English, all models perform well in English.
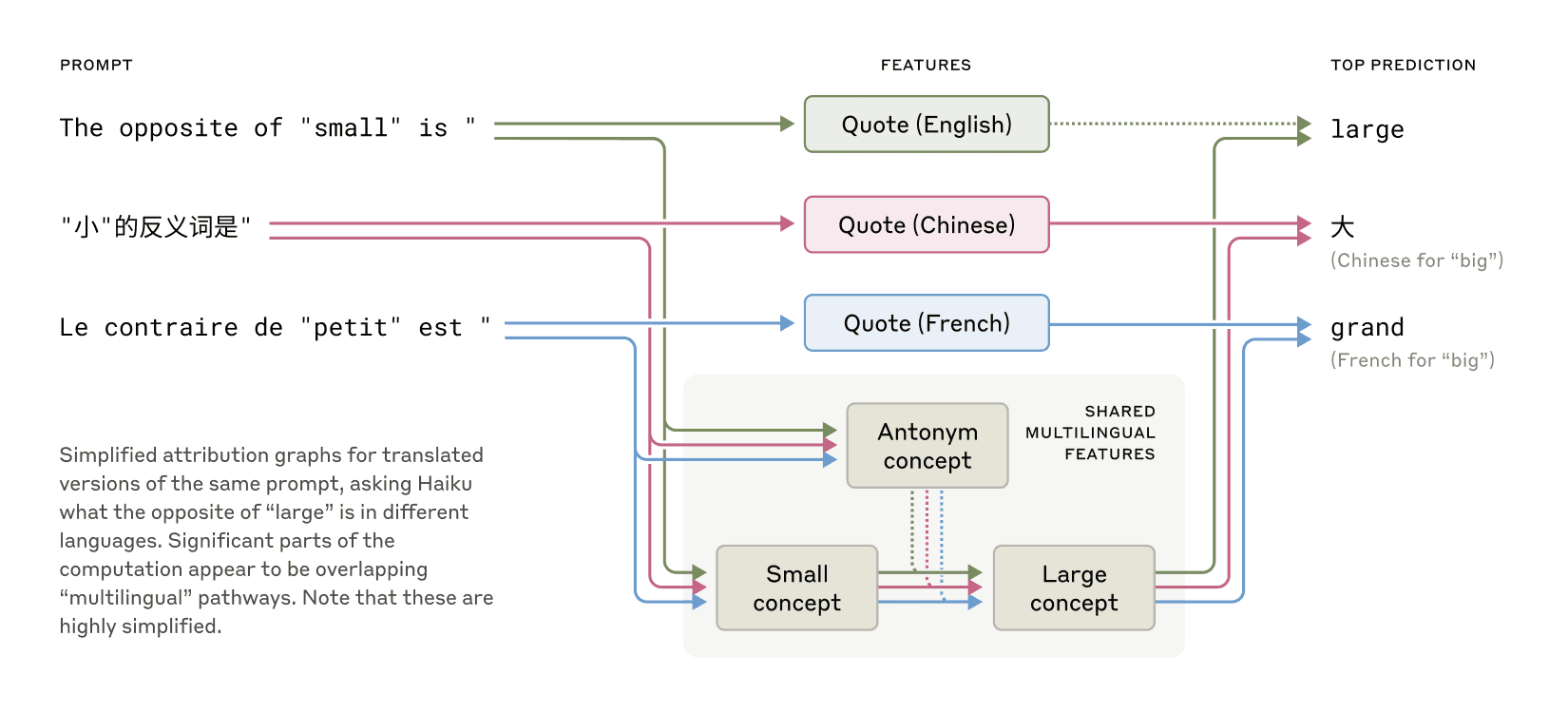
One thing I thought was interesting about this paper [1] on understanding LLMs was how the models associate words/concepts in different languages with each other in what they call Multilingual Circuits.
So the example they give:
English: The opposite of "small" is " → big
French: Le contraire de "petit" est " → grand
Chinese: "小"的反义词是" → 大
Cool graphic for the above [2]
So while English is the lingua franca of the interenet and represents the largest corpus of data, the primary models being built are able to use an English dataset to build associations across languages. This might create significantly stronger AI and reasoning even for languages and regions that lack the data, tech and resources to build local models
You'd be correct. The largest portion of all languages in Common Crawl (aka the "whole open internet" training corpus) is English with 43%. No other language even reaches double digit percentages. The next biggest one is Russian at 6%, followed by German at 5%.
And lots of people write on the web using English as a second language, which both reduces the presence of their native language and increases the presence of English.
Chinese internet mostly consists of a few closed gardens tightly controlled by big corps. Crawlers simply don't work when each company employs an army of engineers to guard their data. Many of the most popular websites are also app only. It's impossible to get the corpus necessary to train a good LLM.
Do we have estimates on the corpus that is available? This model's repo describes "multiple strategies to generate massive diverse synthetic reasoning data." FWIW, AI 2027 forecasts heavy emphasis on synthetic data creation.
Is the lack of existing corpus just an extra hurdle for Hanzi-first models that are also leading the pack in benchmarks?
Likely the case for established model makers, but barring illegal use of outputs from other companies' models, a "first generation" model would still need this as a basis, no?
Why illegal? The more open models (or at least open-weight models) should allow using their outputs. Details depend on license.
But yes, 'first generation' models would be trained on human text almost by definition. My comment was only to contradict the claim that 'all LLMs' are trained from stolen text, by noting that some LLMs aren't trained (directly) on human text at all.
>Or is it that if they publish Chinese-first models it won't get publicity in the West?
This is a large part of it. Kai-Fu Lee's company (https://www.01.ai/) has been publishing open source Chinese language/market focused models pretty early, but the entire conversation around Chinese tech just isn't available to you if you don't speak Chinese, in particular these days given that good English language reporting on the Chinese tech sector just seems very scarce.
One reason is that there is no "good" search engine in China. The most popular one, Baidu, is like garbage compared to Google search. The most useful training data in Chinese would likely be from the social media and video sharing platforms, which I guess is much more difficult to crawl and clean up.
Peanuts compared to the discourse available on the internet.
The literature that survived thousands of years are cream of the crop; you won't find lots of random unimportant dialog between people thousands of years ago, but you find that on Reddit.
Given premodern population sizes and literacy rates, historical texts probably don't exist in anything like the quantity that internet posts do. Even if they did, the information may not be relevant to the modern world.
There's only ONE* Chinese speaking country, at least if you only count those that have a Chinese speaking majority population, or uses Chinese as the official language.
Singapore has a pretty good relationship with China (with all Chinas, actually). And we have plenty of Chinese speakers, too. I'm not sure how prevalent Baidu is, however.
Why are so many American models multi-lingual, supporting hundreds of languages not commonly spoken in the United States?
Could it be that being multilingual results in a larger pool of human knowledge on the technical side compared to training on just a single language or 2. And on the business side, supporting more languages results in a larger TAM (total addressable market). Using english-language dataset for training LLMs is the default, not the other way like you insinuate.
That's clearly a different question. It'd be possible for these models to be Mandarin-first while still supporting other languages, like American models are English-first while doing the same, but that's not what's happening.
> That's clearly a different question. It'd be possible for these models to be Mandarin-first while still supporting other languages
What would a hypothetical "Mandarin-first" model look like to you?
I challenge the notion that the current models are "English-first" - that is an unsubstantiated opinion not supported by fact. I bet, dollars to donuts, these models are SoTA in Mandarin as well. When framed that way, asking "Why are they marketed as English-speaking models outside of China" or "Why are they really good at English" are simply not interesting questions - they have obvious answers.
"12 + 89" uses the latin alphabet and is in no way language-agnostic in this context. I expect borrowed constructs to appear relatively more frequently in the language they were borrowed from.
Now I'm curious how Mistral models would respond to a "language-agnostic" phrases like "Rendezvous" or "coup d'etat"
You may think of these symbols as "Latin" because they're how people writing in Latin script happen to write mathematical expressions, but the exact same symbols are also used by Mandarin speakers, as well as in numerous other scripts. Writing math in Chinese characters is literally as uncommon as someone writing "twelve plus eighty-nine" in English.
In contrast, your examples would be spelled « rendez-vous » and « coup d’État » in French, i.e. easily distinguishable from their English descendants.
> You may think of these symbols as "Latin" because they're how people writing in Latin script happen to write mathematical expressions
No need for scare-quotes, Latin script is a proper noun and a technical term with precise meaning wrt text encoding - not "what I think."
> the exact same symbols are also used by Mandarin speakers, as well as in numerous other scripts. Writing math in Chinese
Which unicode code points do the Mandarin speakers and "numerous other scripts" use to write "12 + 89"? Could it be the very same code points as Latin script, which then are tokenized to the same vectors that the LLMs learn to associate more with English text rather than CJK in the latent space?
> i.e. easily distinguishable from their English descendants.
You're making broad assumptions about the tokenization design here that do not apply universally.
Precisely because the exact same codepoints are used for digits and mathematical symbols, there's nothing script-specific about them and their linguistic association is determined by the training data mixture. A model trained predominantly on text scraped from Chinese websites would learn to associate them more with Mandarin than English in the latent space, since that would be the context where they most often appear.
This smacks of "I saw a headline once"-itis. Especially the fact that you refer to the Chinese characters as "calligraphy characters", as if that were the general term or something.
None of these really mean that English has won, though. Rather that phonetics-based writing systems are easier to remember and use, especially in conjunction with digital systems that make it easy to map sound and context to symbols.
I wouldn't be surprised if characters are faster to read though. In English we have all these subconscious shortcuts like looking at the shape of the word, first and last letters, etc. But I think symbology can convey more at a glance. Thus the popularity of emoji
Ah no, I know myself that there have been headlines here and there.
I'm pretty sure there was some controvery in the linguistic blogging community even at some stage over the last couple of years, with someone writing an essay claiming the Chinese character system was in some sense less advanced and maybe on the way out, and this leading to a serious response or two, the usual fiery academic affair. I can't locate it this instant though.
I moreso meant for OP's low-effort dramatisation to not go unanswered. Framing it as "winning" some sort of language battle is particularly silly.
Your musings are interesting though, and the topic certainly is a fascinating one. Languages that use morphemes for writing are wild. Symbology is a cool word also - surely there has to be a lisp blog somewhere with that word in the title.
The pendulum already turned back. The current generation under 20 grew up with touchscreens. That obseletes input with pinyin; many don't care if the device has no keyboard.
Input is so interesting in China, basically a sorta t9 but just single letters and picking the right characters, with common/frequently used characters first, using pinyin. For example to say “ How are you?” You just type “nhm” (Ni Hao Ma) and 你好吗 shows up as suggestion/autofill. You can make surprisingly long sentences using this method.
Uh? Pinyin input is by far the most popular input technique in China. I rarely see anyone using handwriting input.
That being said, it has nothing to do with English winning. It's just a Chinese input technique that uses the latin alphabet. English fluency in China is not very common, especially spoken English.
My father-in-law here in China uses handwriting input, but everyone else I've seen here uses Pinyin, and it's totally fast and natural for them.
And very true about the English. With some exceptions (of course), folks here maybe know a handful of words at best, and even then, pronunciation is usually pretty rough. People here really aren't using it; they are perfectly comfortable with their Chinese, and why wouldn't they be?
Anyone saying otherwise clearly hasn't been here to see it firsthand.
By the looks of it, Pinyin (a phonetic one) won by a landslide, which I suspect this is the result of a long effort by the Chinese government to install Mandarin as the official language of China, above regional dialects (different regions would write similar characters but pronounce them differently, and defaulting to Pinyin has this "nice" effect of having people "think of how it would be pronounced in Mandarin first", even when the result are characters that would be read by a Cantonese speaker).
This is not true. I was in Beijing around then and never met a single person who spoke English if they hadn't learned it for professional reasons (they worked in tourism, international business, etc.).
It could not have been further from a bilingual society.
I suppose you probably were visiting some university districts/CBDs where people likely to have received higher education. Elsewhere, aside from basic "hello"/"how are you", locals in general are not able to communicate in English.
Not sure which part you were in, but this is just not true in my experience. I've been to Beijing, Shenzhen, Guangzhou, and some others, and Mandarin really is a must if you want to even have a chance of communicating. I can't imagine how I'd function here if I only had English.
I've not yet been to Shanghai, and while I would expect the English-speaking percentage to be a bit higher, it would still likely only be in the single-digits by my estimation.
The mandarin language models obviously exist, but what would you do with them if they provided access to them? And what knowledge would be in them? What is the body of knowledge encoded in Mandarin? What does that look like?
Sad reality is that not many outside of China have the facility with Mandarin to use those models. Even non-native Mandarin speakers who claim to be "fluent", are often messing up intended meaning in text. Or making literal translations that wind up making no sense.
Inside of China, llm use will be Mandarin based. Outside, it seems to me English is the natural choice.
Irony of Irony, probably the best way for a non Mandarin speaking layman to test a Mandarin based model would be to use another LLM to translate prompts to Mandarin.
For it to be brilliant, AI needs to be a benevolent tool all the time. It would take just a few malignant actors to turn our world upside. I suspect it'll follow the same Internet and social media path. Great at first, grow markets, bring us together and then take a turn.
> Even non-native Mandarin speakers who claim to be "fluent", are often messing up intended meaning in text. Or making literal translations that wind up making no sense.
Happens with English as well, but non-native speakers of English still benefit from these models.
{kind=link}