If the goal is simply to make social media unprofitable, you can just be really brutal and require that all users from a language region visiting a website (or using an App) must be delivered the exact same set of ads.
The fact that most advertisers would flock to promoting on smaller special websites/apps (equivalent to your gardening magazine), is exactly the side-effect we want. The shift in spending will hopefully lead to the current "massive social media platform" model will dying out, and boosting smaller independent platforms.
Smaller platforms are worse at optimizing for engagement. It's one of those weird situations where it's a good idea precisely because it's economically inefficient.
Only problem with that approach is that assume_init() is unsafe (because it depends on you getting the initialisation loop correct), and many people are (correctly) hesitant to use unsafe.
IMO, it would be really nice if the naive syntax was guaranteed to work, rather than requiring programmers to remember a new workaround syntax (new_uninit_slice() was only stabilised a year ago). This edge case is a little annoying because the naive approach will usually work for a release build, but then fail when you with back to a debug build.
Yes, sorry, too late to edit now but it should use an unsafe block for the assume and provide the safety rationale explaining why we're sure this is correct.
I am sympathetic to desire to make it "just work" in proportion to how much I actually see this in the wild. Large heap allocations, initialized in place in a single sweeping action. It does happen, but I don't reach for it often.
Often people say "Oh, well I will finish initializing it later but..." and now we're definitely talking about MaybeUninit 'cos if you've only half finished the Goose, that's not a Goose yet, that's a MaybeUninit<Goose> and it's crucial that we remember this or we're writing nonsense and may blow our feet off with a seemingly harmless mistake elsewhere.
But I'm not sure it's worth porting your code to Fil-C just to get that property. Because Fil-C still needs to track the memory allocation with its garbage collector. there isn't much advantage to even calling free. If you don't have a use-after-free bug, then it's just adding the overhead of marking the allocation as freed.
And if you do have a use-after-free bug, you might be better off just letting it silently succeed, as it would in any other garbage collected language. (Though, probably still wise to free when the data in the allocation is now invalid).
IMO, if you plan to use Fil-C in production, then might as well lean on the garbage collector. If you just want memory safety checking during QA, I suspect you are better off sticking with ASan. Though, I will note that Fil-C will do a better job at detecting certain types of memory issues (but not use-after-free)
I wasn’t talking about use-after-free, I was talking about memory leaks - when you get a pointer from malloc(), and then you destroy your last copy of the pointer without ever having called free() on it.
Can the GC be configured to warn/panic if it deallocates a memory block which the program failed to explicitly deallocate?
Question , would this be a desirable outcome for drivers. As far as i can tell most kernel driver crashes are the ones that would benefit from such protection.Plus obviate the need to do full rewrites - if such a GC can protect from the faults and help with the recovery.Assuming the GC after recovery process is similar to erlang BEAM where a reload can bring back healthy state.
Motor rotation isn't quite enough, as it's not aligned to the sectors on the disk.
Drives which do skip indexing (Like Apple's Disk II) use the actual data on the disk for indexing. Each sector header has a track/sector/head ID, allowing the controller to know where it is on the disk without the need for indexing.
TBH, I'm not sure PC floppies even use the index pulse for anything other than formatting the disk. Once the disk is formatted, it's kind of redundant information. But it's required by the spec, forcing PC floppy drives to include the sensor.
The motor signal not being aligned to sectors of the disk doesn't matter because the drive doesn't care about angular position. The track header is generally not used for anything, on PC drives it's ignored and can be left out if you want to fit a few more bytes on the drive.
Unlike hard disk drives that use servo data to decide where to read and write, floppy disk drives generally don't know the angular position of either the drive or the sectors and use an extremely simple algorithm. In a very real way, they work like tape drives except they can freely choose one from a bunch of circular tapes to work on.
When ordered to read a specific sector, the drive seeks to the track requested, and then reads the track continuously until it sees the sector header magic value. Then it compares the track and sector numbers after that header with the requested numbers, and if they match, it waits for the magic value (000000000000000000A1A1A1F{AB}) and then starts reading. The magic number is designed to reinitialize the PLL, and also give the drive electronics enough time to make the comparison and decision of whether to do anything. If the numbers didn't match what was requested, then it just keeps reading until it has received a defined amount of pulses from the motor, usually 2 or 3, at which point it returns an error.
The sectors don't have any defined order on the track. You can do weird things like order your sectors linearly except have one specific one out of order, have multiple sectors with the same sector number on the same track (in which case which is returned on read depends on which you happen to hit first), have a sector with the wrong track id on a track (that gets ignored by normal read/write commands, but can be accessed with low-level ones), index your sectors with a set of random numbers between 1 and 255 instead of sticking to 1-18, and plenty more. All these have been used in various hare-brained copy protection schemes. The drive electronics are too simple to care, they just compare one number with another and do a single decision based on it.
Everything it says about cache coherency is exactly the same on ARM.
Memory ordering has nothing to do with cache coherency, it's all about what happens within the CPU pipeline itself. On ARM reads and writes can become reordered within the CPU pipeline itself, before they hit the caches (which are still fully coherent).
ARM still has strict memory ordering for code within a single core (some older processors do not), but the writes from one core might become visible to other cores in the wrong order.
I’m of the opinion that it’s unlikely to happen within 50 years.
But I still think it’s a good idea to start switching over to post-quantum encryption, because the lead time is so high. It could easily take a full 10 years to fully implement the transition and we don’t want to be scrambling to start after Q-day.
Moving from SHA-1 to SHA-2 took ~20 years - and that's the "happy path", because SHA-2 is a drop-in replacement.
The post-quantum transition is more complex: keys and signatures are larger; KEM is a cryptographic primitive with a different interface; stateful signature algorithms require special treatment for state handling. It can easily take more than 20 years.
> Instructions are more easily added than taken away.
That's not saying much, it's basically impossible to remove an instruction. Just because something is easier than impossible doesn't mean that it's easy.
And sure, from a technical perspective, it's quite easy to add new instructions to RISC-V. Anyone can draft up a spec and implement it in their core.
But if you actually want wide-spread adoption of a new instruction, to the point where compilers can actually emit it by default and expect it to run everywhere, that's really, really hard. First you have to prove that this instruction is worthwhile standardizing, then debate the details and actually agree on a spec. Then you have to repeat the process and argue the extension is worth including in the next RVA profile, which is highly contentious.
Then you have to wait. Not just for the first CPUs to support that profile. You have to wait for every single processor that doesn't support that profile to become irrelevant. It might be over a decade before a compiler can safely switch on that instruction by default.
It's not THAT hard. Heck, I've done it myself. But, as I said, the burden of proof that something new is truly useful quite rightly lies with the proposer.
The ORC.B instruction in Zbb was my idea, never done anywhere before as far as anyone has been able to find. I proposed it in late 2019, it was in the ratified spec in later 2021, and implemented in the very popular JH7110 quad core 1.5 GHz SoC in the VisionFive 2 (and many others later on) that was delivered to pre-order customers in Dec 2022 / Jan 2023.
You might say that's a long time, but that's pretty fast in the microprocessor industry -- just over three years from proposal (by an individual member of RISC-V International) to mass-produced hardware.
Compare that to Arm who published the spec for SVE in 2016 and SVE 2 in 2019. The first time you've been able to buy an SBC with SVE was early 2025 with the Radxa Orion O6.
In contrast RISC-V Vector extension (RVV) 1.0 was published in late 2021 and was available on the CanMV-K230 development board in November 2023, just two years later, and in a flood of much more powerful octa-core SpacemiT K1/M1 boards (BPI-F3, Milk-V Jupiter, Sipeed LicheePi 3A, Muse Pi, DC-Roma II laptop) starting around six months later.
The question is not so much when the first CPU ships with the instruction, but when the last CPU without it stops being relevant.
It varies from instruction to instruction, but alternative code paths are expensive, and not well supported by compilers, so new instructions tend to go unused (unless you are compiling code with -march=native).
In one way, RISC-V is lucky. It's not that currently widely deployed anywhere, so RVA23 should be picked up as the default target, and anything included in it will have widespread support.
But RVA23 is kind of pulling the door closed after itself. It will probably become the default target that all binary distributions will target for the next decade, and anything that didn't make it into RVA23 will have a hard time gaining adoption.
I'm confused. You appear to be against adding new instructions, but also against picking a baseline such as RVA23 and sticking with it for a long time.
Every ISA adds new instructions over time. Exactly the same considerations apply to all of them.
Some Linux distros are still built for original AMD64 spec published in August 2000, while some now require the x86-64-v2 spec defined in 2020 but actually met by CPUs from Nehalem and Jaguar on.
The ARMv8-A ecosystem (other than Apple) seems to have been very reluctant to move past the 8.2 spec published in January 2016, even on the hardware side, and no Linux distro I'm aware of requires anything past original October 2011 ARMv8.0-A spec.
I'm not against adding new instructions. I love new instructions, even considered trying to push for a few myself.
What I'm against is the idea that it's easy to add instructions. Or more the idea that it's a good idea to start with the minimum subset of instructions and add them later as needed.
It seems like a good idea; Save yourself some upfront work. Be able to respond to actual real-world needs rather than trying to predict them all in advance. But IMO it just doesn't work in the real world.
The fact that distros get stuck on the older spec is the exact problem that drives me mad, and it's not even their fault. For example, compilers are forced generate some absolute horrid ARMv8.0-A exclusive load/store loops when it comes to atomics, yet there are some excellent atomic instructions right there in ARMv8.1-A, which most ARM SoCs support.
But they can't emit them because that code would then fail on the (substantial) minority of SoCs that are stuck on ARMv8.0-A. So those wonderful instructions end up largely unused on ARMv8 android/linux, simply because they arrived 11 years ago instead of 14 years ago.
At least I can use them on my Mac, or any linux code I compile myself.
-------
There isn't really a solution. Ecosystems getting stuck on increasingly outdated baseline is a necessary evil. It has happened to every single ecosystem to some extent or another, and it will happen to the various RISC-V ecosystems too.
I just disagree with the implication that the RISC-V approach was the right approach [1]. I think ARMv8.0-A did a much better job, including almost all the instructions you need in the very first version, if only they had included proper atomics.
[1] That is, not the right approach for creating a modern, commercially relevant ISA. RISC-V was originally intended as more of an academic ISA, so focusing on minimalism and "RISCness" was probably the best approach for that field.
It takes a heck of a lot longer if you wait until all the advanced features are ready before you publish anything at all.
I think RISC-V did pretty well to get everything in RVA23 -- which is more equivalent to ARMv9.0-A than to ARMv8.0-A -- out after RV64GC aka RVA20 in the 2nd half of 2019.
We don't know how long Arm was cooking up ARMv8 in secret before they announced it in 2011. Was it five years? Was it 10? More? It would not surprise me at all if it was kicked off when AMD demonstrated that Itanium was not going to be the only 64 bit future by starting to talk about AMD64 in 1999, publishing the spec in 2001, and shipping Opteron in April 2003 and Athlon64 five months later.
It's pretty hard to do that with an open and community-developed specification. By which I mean impossible.
I can't even imagine the mess if everyone knew RISC-V was being developed from 2015 but no official spec was published until late 2024.
I am sure it would not have the momentum that it has now.
it's basically impossible to remove an instruction.
Of course not. You can replace an instruction with a polyfill. This will generally be a lot slower, but it won't break any code if you implement it correctly.
While I agree with you, the original comment was still valuable for understanding why RISC-V has evolved the way it has and the philosophy behind the extension idea.
Also, it seems at least some of the RISC-V ecosystem is willing to be a little bit more aggressive. With Ubuntu making RVA23 the minimum profile for Ubuntu, perhaps we will not be waiting a decade for it to become the default. RVA23 was only ratafied a year ago.
Multiuser machines could get away with surprisingly little memory; They had some major advantages over home computers:
Users were all connected via CRT terminals over serial, so you didn't need to waste any memory on screen buffers. This also reduced CPU usage as the user wouldn't get any CPU time until they pressed a key, and the scheduler might queue up multiple key presses before even switching to the user's task (while still showing immediate feedback)
They also had superior IO. Home computers were connected to slow floppy drives (at best, some were still using tape) so they typically tried to keep the whole working set in memory. But multi-user machines had relatively fast hard drives and could afford to shuffle the working set in and out of memory as needed, with DMAs handling the actual transfer in the background.
As others have pointed out, these machines had bank switching. But I doubt such machines were ever configured with more than 256k of memory, with 128k being more typical. Wikipedia claims 32k was the absolute minimum, but with very little free memory, so I suspect 64k would be enough for smaller offices with 4-6 users.
AMD named their memory fabric "infinity fabric" for marketing reasons. So when they developed their memory attached cache solution (which lives in the memory fabric, unlike a traditional cache), the obvious marketing name is "infinity cache"
The main advantage of a memory attached cache is that it's cheaper than a regular cache, and can even be put on a seperate die, allowing you to have much more of it.
AMDs previous memory fabric from the early 2000s was called "Hyper Transport", which has a confusing overlap with Intel's Hyper Threading, but I think AMD actually bet intel to the name by a few years.
Infinity Fabric is, in fact, the current superset of HyperTransport. HyperTransport is an IO architecture for chip to chip communication and has been used by pretty much everyone. It's also an open spec and has a consortium managing it.
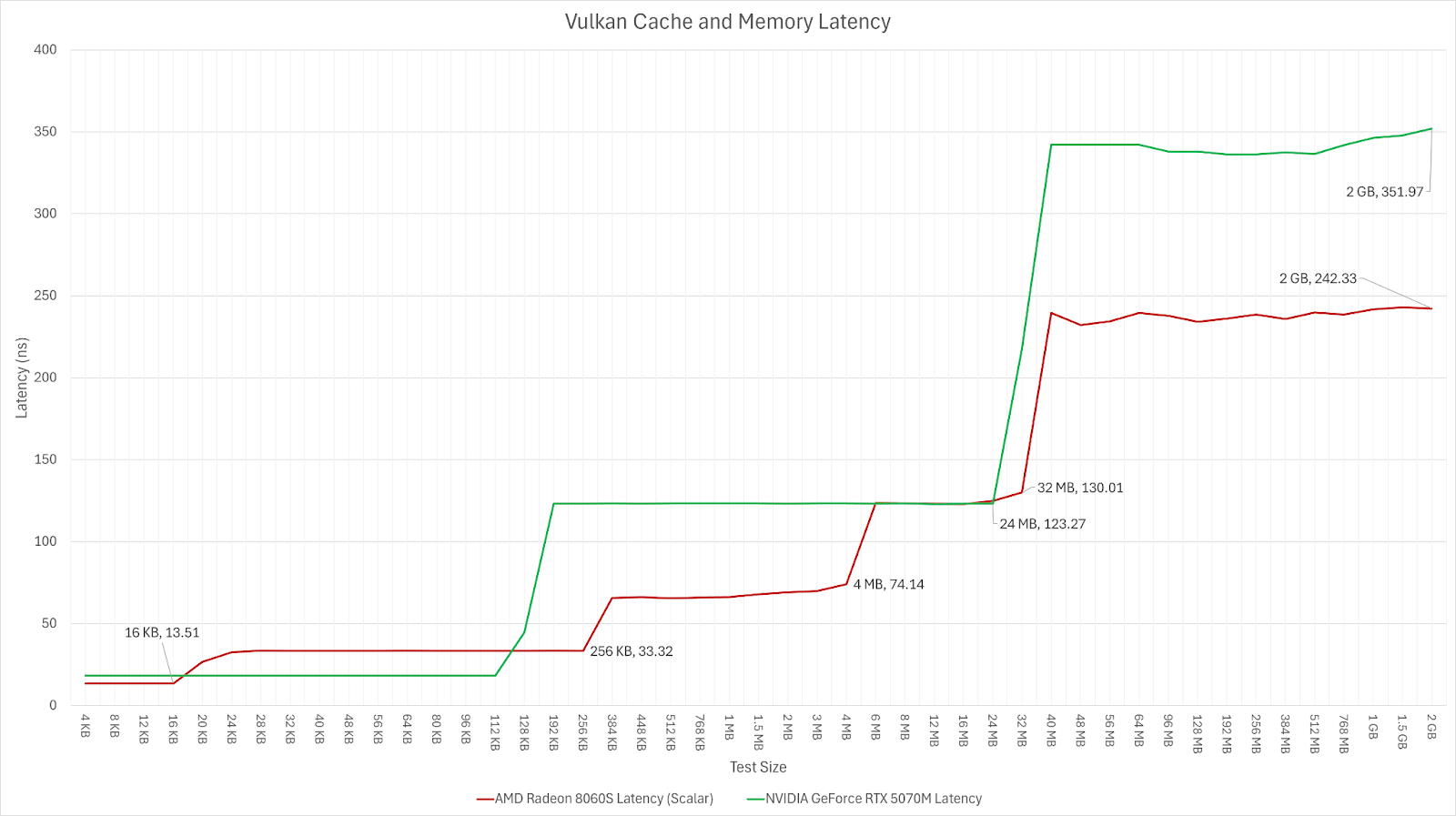
Not sure if ditching infinity cache/L3 for a bigger L2 would make sense. It seems at least plausible to me that growing the L2 cache that much would make its latency worse, thus losing most of what has been gained. In the image you linked, Nvidia's L2 latency is like twice as high as AMD's!
Keep in mind that the 'big' desktop chips have bigger caches too. The L2 on a 5080 and 'L3' on a 9070 XT are both 64 MB. Additionally, AMD has already been growing the L2, going to 8 MB on the 9070 XT vs. 4 MB on the 7800 XT and 6800 XT.
To clarify, the idea that AMD is ditching IC is not mine, I find it puzzling too.
Their marketing materials to OEMs have been leaked, and they no longer mention IC at all, instead proudly displaying (much higher) L2 amounts per GPU. This of course doesn't necessarily mean that they are definitely removing it, but it certainly hints at that.
The manufacturer didn’t even know encryption was enabled, because as long as the camera was working, it would just provide all files over USB without any encryption.
It was basically enabled by accident, and the only thing it prevented was recovery of files directly from the SD card when the camera was damaged.
{kind=link}
The fact that most advertisers would flock to promoting on smaller special websites/apps (equivalent to your gardening magazine), is exactly the side-effect we want. The shift in spending will hopefully lead to the current "massive social media platform" model will dying out, and boosting smaller independent platforms.
reply